
Feature Requests
- Previously, for publicly-available content, selecting the "Exclude from search results" option for content would remove it from search within KnowledgeOwl but might still lead to Google search indexing it. Selecting that option now adds a
<meta name="robots" content="no index">tag to the header for the article, preventing search engines from indexing it.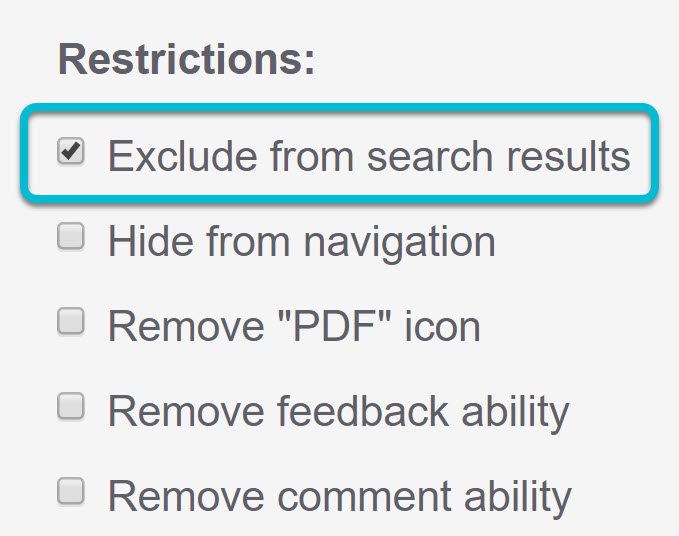 Change this setting in the article editorNote: if any of your excluded-from-search content is already indexed by search engines, you'll need to request a recrawl of your site for them to respect this change.
Change this setting in the article editorNote: if any of your excluded-from-search content is already indexed by search engines, you'll need to request a recrawl of your site for them to respect this change. - For advanced authors/developers: we've added an object-id merge code so you can pull the ID of an article or category that's currently being viewed.

Bug Fixes
- Administrative authors accessing app.knowledgeowl.com will now see a warning if your session has logged out due to inactivity or logging out in a separate tab. The warning will prompt you to log back in in a separate window so that you can log back in without losing any work.
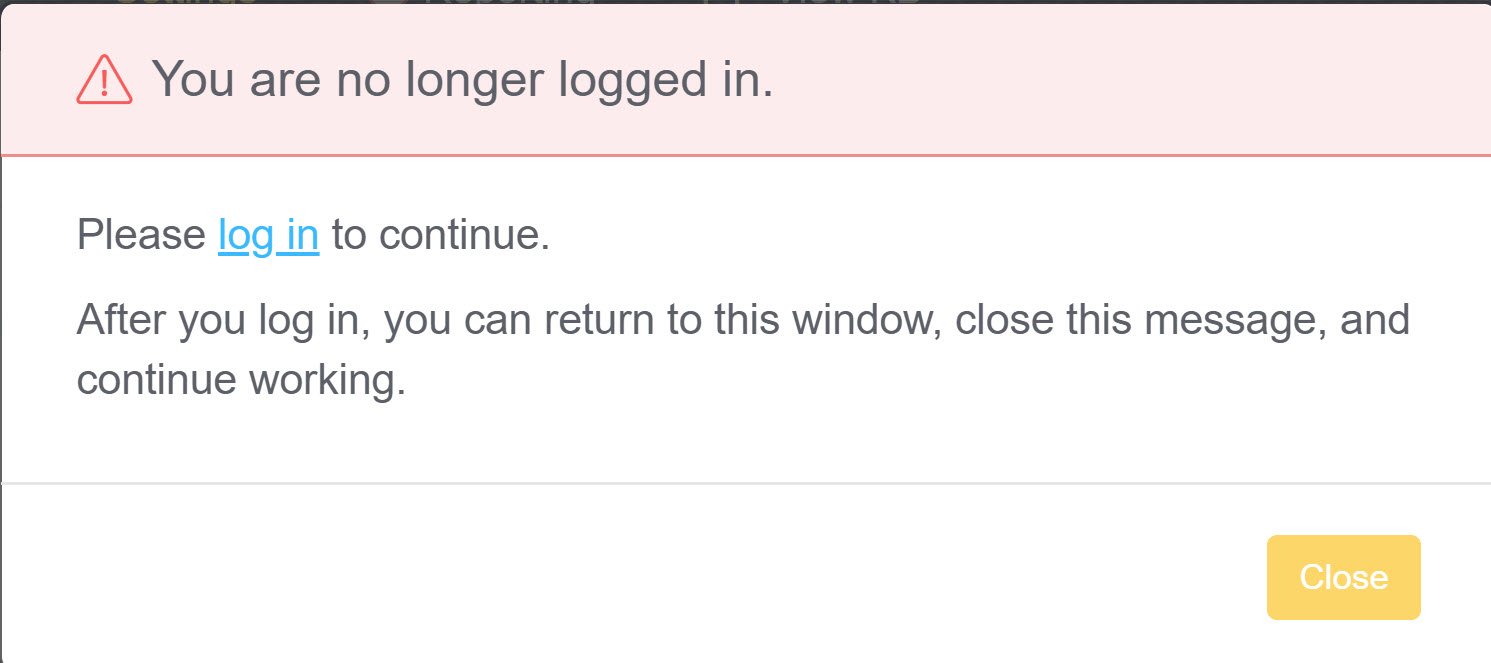 Sample idle session pop-up
Sample idle session pop-up - In PDFs, hyperlinks appearing at the end of a paragraph or list item were sometimes showing HTML tags or truncated content. Hyperlinks at the end of paragraphs and list items now behave like proper hyperlinks. Resaving an affected article with a small change will regenerate the PDF to use the fix, but if you think a lot of your PDFs were impacted, contact us to request a bulk regeneration of all PDFs.
- Numeric permalinks beginning with 0 weren't working properly. Now they are.
